学校的服务器没给ROOT权限,这让很多操作受限,但得益于Linux优秀的系统特性,即使是普通用户也可以在权限允许的范围内运行ollama
本文使用的服务器配置在如何使用你的深度学习服务器一文中有所提及,故部分基础命令此处不再提及
部署ollama
由于没有ROOT权限,一键脚本是用不得了,只能手动部署
首先新建个文件夹来放ollama
1 | mkdir -p ~/ollama && cd ~/ollama |
服务器如果可以连上Github最好不过,可以用wget拉取ollama
1 | wget -O ollama-linux-amd64.tgz https://ollama.com/download/ollama-linux-amd64.tgz |
服务器要是不能连上Github,可以先把ollama-linux-amd64.tgz下载到本地,再用sftp(或类似工具)上传到服务器
下载/上传完成后,解压压缩包
1 | tar -xvzf ollama-linux-amd64.tgz |
解压完后,ollama文件夹下应该有bin和lib两个文件夹
使用如下命令启动ollama
1 | ./bin/ollama serve |
示例输出如下(未指定GPU时默认使用全部的GPU)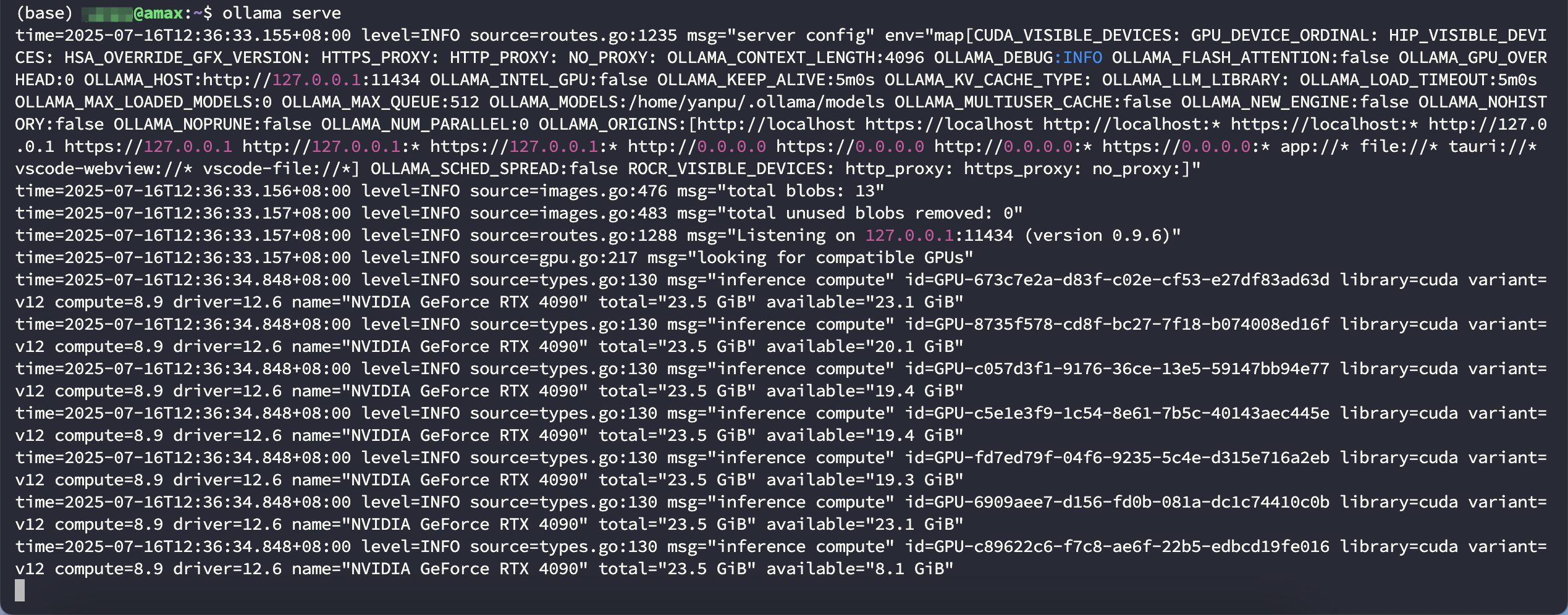
再新建一个终端,进入ollama文件夹,运行命令就能看到ollama版本
1 | ./bin/ollama --version |
 ollama 0.9.6
ollama 0.9.6
配置环境变量
如果只是临时用一下ollama,此节内容可选看
编辑配置文件
1 | vim ~/.bashrc |
在最下面插入内容,从第三行到第五行是可选变量,视实际情况使用;如第四行,家用计算机通常只有一块GPU就不需要指定GPU了
1 | export OLLAMA_HOME=部署ollama的位置 |
使刚编辑的环境变量生效
1 | source ~/.bashrc |
GPU实时监控
Linux系统并不好实时监控GPU,所以需要辅助工具,比较推荐的是nvitop
nvidia-smi
nvidia-smi是系统工具,但不能实时监控是其一个缺点,可以通过设置定时刷新来弥补这一点
1 | nvidia-smi -l |
上述命令会显示历史信息,如果你只想看当前信息,可以执行
1 | watch -n 1 nvidia-smi |
nvitop
nvitop甚至不需要apt install,它只作为python的一个库安装
1 | pip3 install nvitop |
查看GPU状态
1 | nvitop |
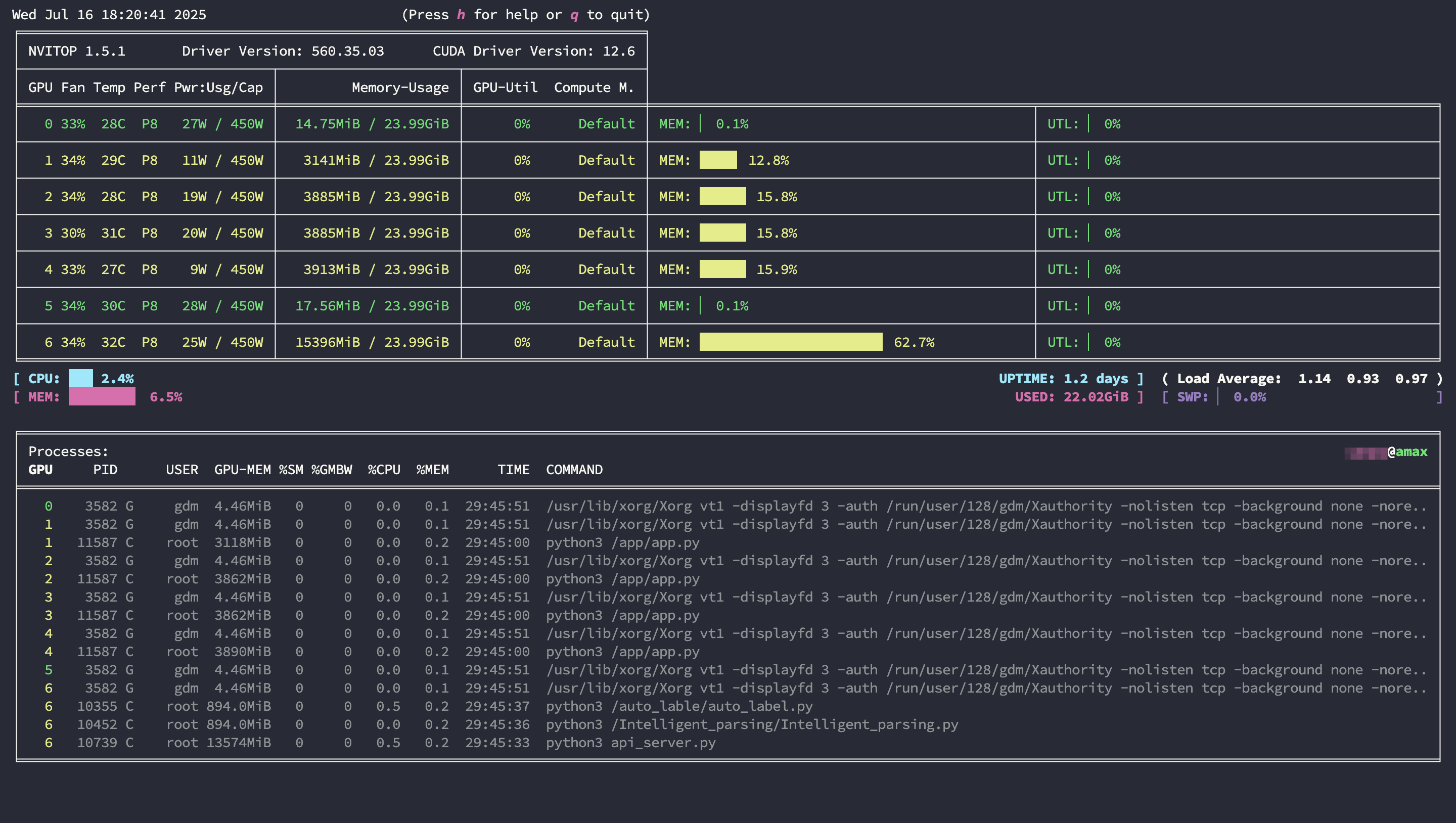
gpustat
如果不想看到完整信息,仅仅是想监控GPU的运行状态,那么gpustat也是个不错的选择
可以作为系统的包进行安装(需要ROOT权限):
1 | sudo apt install gpustat |
也可作为Python库进行安装:
1 | pip3 install gpustat |
运行gpustat时需要带参数才能显示实时信息
1 | gpustat -i |
后台服务
总是开两个终端,一个运行ollama serve,另一个运行ollama其他命令还是太麻烦,可以使用systemd在后台运行ollama,配合环境变量,使ollama的调用更方便
编辑 ~/.config/systemd/user/ollama.service
1 | [Unit] |
服务管理常用命令
1 | systemctl --user daemon-reload # 重载配置 |
端口映射
没有ROOT权限不能操作防火墙,导致没办法远程访问服务器上ollama端口,只好通过SSH在本地对服务端口进行映射
一般默认远程SSH的22端口、用密码登陆的Linux服务器可以使用如下命令转发服务器上的端口
1 | ssh -N -L 11434:localhost:11434 username@ip |
倘若贵校的服务器管理非常严格(此处没有暗指某医科类大学),不仅更换了远程SSH端口,还要求使用密钥登陆,那么应当使用如下命令来转发服务器端口
1 | ssh -N -L 11434:localhost:11434 \ |
这样能在本地的11434端口访问到服务器上运行的ollama服务了
在ollama上运行模型
此节默认配置好了ollama的环境变量
一些基础命令
ollama一些基础命令如下,更详细的命令可以参照菜鸟教程 Ollama 相关命令
1 | ollama list # 列出所有模型 |
 拉取deepseek-r1:32b模型
拉取deepseek-r1:32b模型
模型选择
尽量根据自己的硬件情况选择模型,最好在运行前确保不会爆显存
以下是一个简单的常用模型的对应表格(它并不准确,只是一张大致的对应表格!),更多的模型和更详细的参数可以在ollama官网中找到
| 模型名称 | 参数规模 | 完整版显存需求 | 量化版显存需求 | 量化类型 | 最低显卡配置 | 推荐显卡配置 |
|---|---|---|---|---|---|---|
| Llama3 | 405B | 810GB+ | 200GB | 8-bit | 8×H100 80G | 16×A100 80G |
| 70B | 140–160GB | 24GB | 4-bit | 8×P40 | 8×A10 | |
| 33B | 66GB | 16GB | 4-bit | 1×A100 80G | 2×RTX 4090 | |
| 8B | 16–20GB | 6GB | 4-bit | RTX 3060 12G | RTX 3090/4090 | |
| 4B | 8GB | 4GB | 4-bit | GTX 1080 Ti | RTX 3060 12G | |
| DeepSeek‑R1 | 671B | 1.3–1.6TB | 436GB | 4-bit | 32×H100 80G | 多节点分布式集群 |
| 70B | 280–350GB | 80GB | 4-bit | 8×A100 80G | 8×A10 | |
| 32B | 128–160GB | 20GB | 4-bit | 4×A100 40G | 2×RTX 4090 | |
| 8B | 32–40GB | 6GB | 4-bit | RTX 3060 12G | RTX 3090/4090 | |
| Qwen3 | 235B (MoE) | 470GB | 110GB | 4-bit | 16×A100 80G | 专业计算集群 |
| 32B | 64GB | 16GB | 4-bit | 1×A100 80G | 2×RTX 4090 | |
| 8B | 16GB | 5GB | 4-bit | GTX 1080 Ti | RTX 3060 12G | |
| 4B | 8GB | 3GB | 4-bit | 集成显卡 | GTX 1660 |
可以使用以下命令评估模型的生成速率
1 | ollama run <model-name> --verbose |
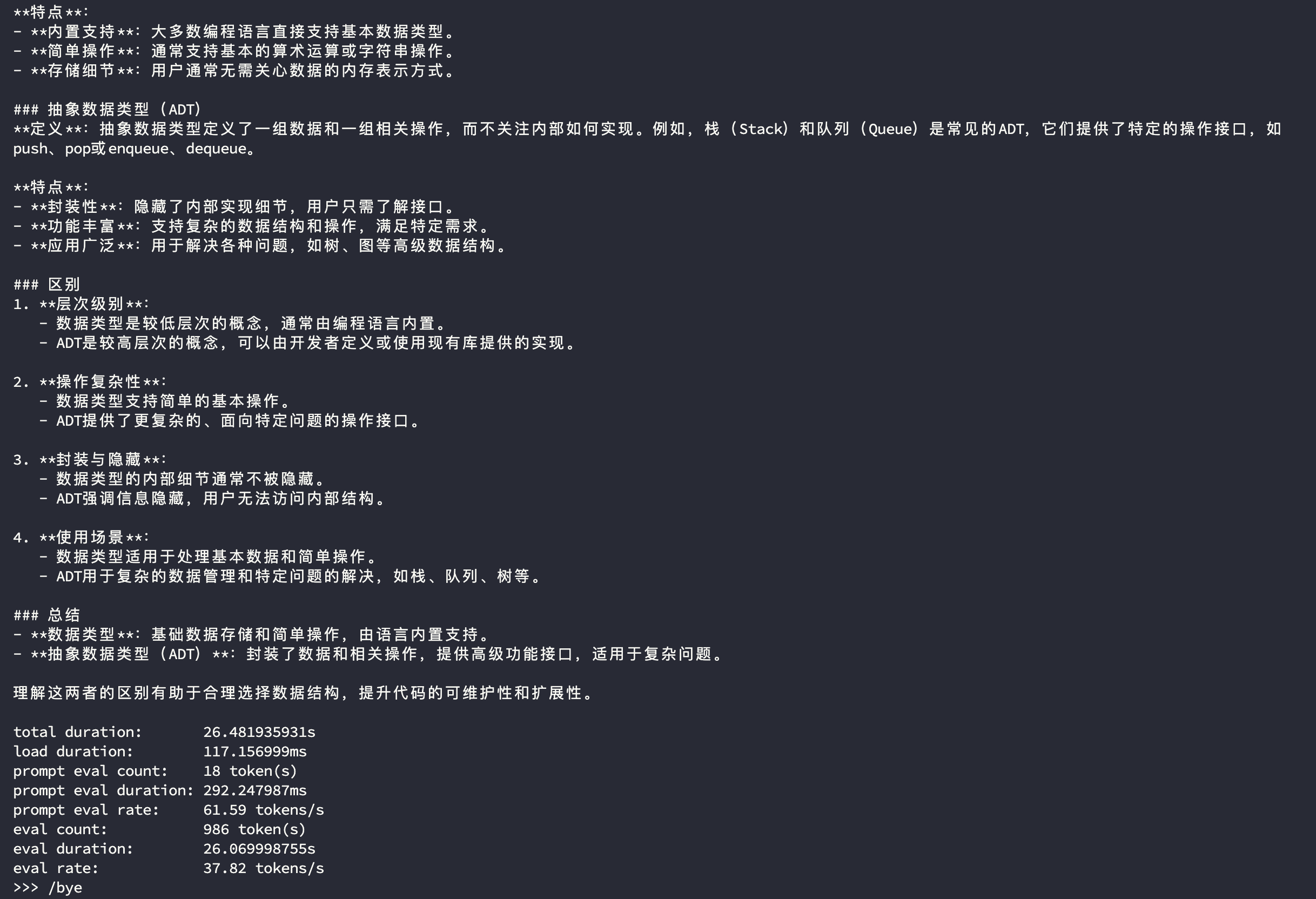 deepseek-r1:32b的生成速率
deepseek-r1:32b的生成速率
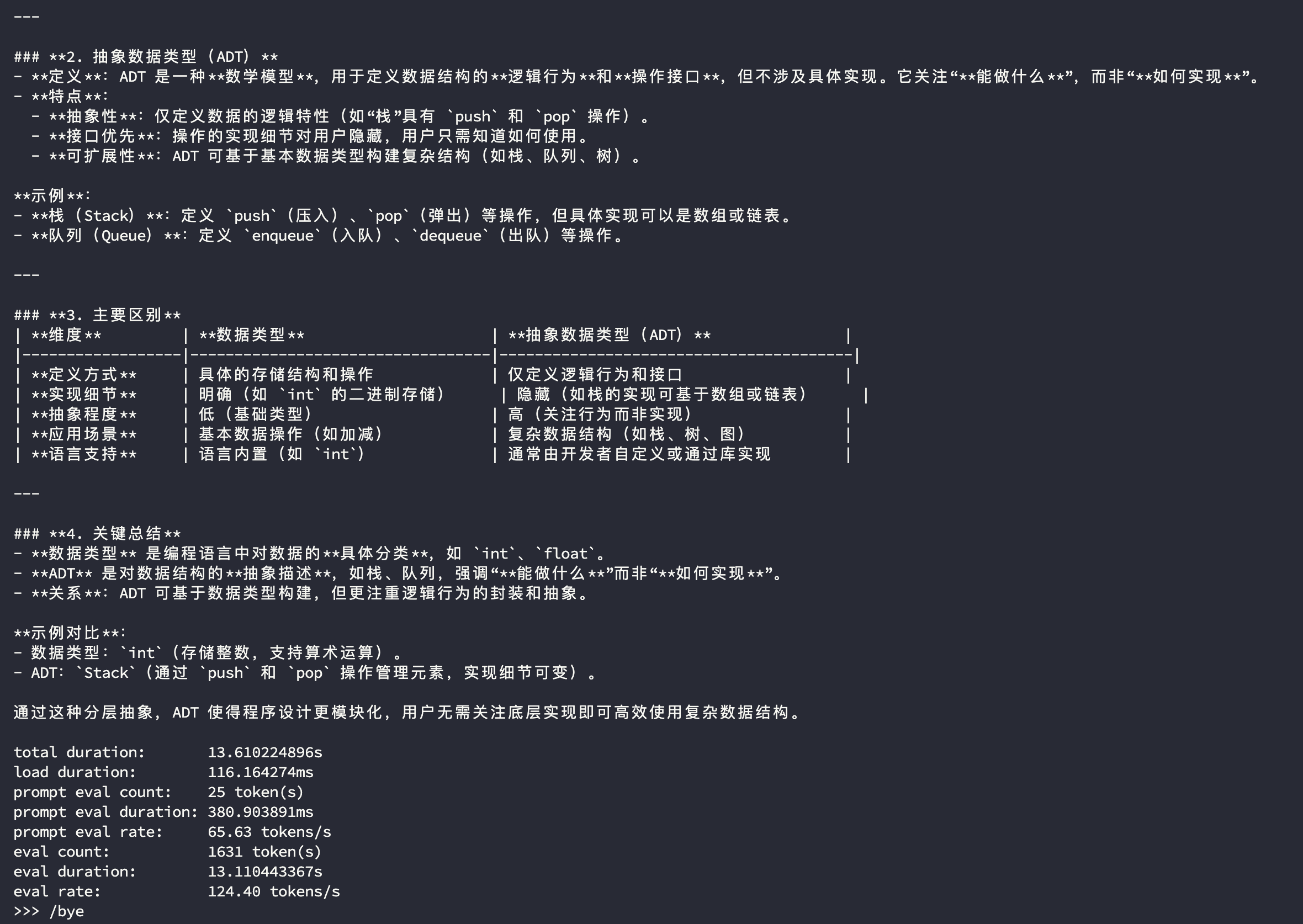 qwen3:30b-a3b的生成速率
qwen3:30b-a3b的生成速率
虽然只测试了生成速率,但也可以从回答中看出来 Qwen3 30B A3B(q4_K_M) 模型相较于同等量化级别的 DeepSeek R1 32B Qwen Distill(q4_K_M) 在使用单张 RTX 4090 时的表现更好
使用python调用ollama上的模型
此处我构建了一个简单的python脚本,主要是为了测试ollama上的模型,如果想实际使用请考虑open-webui
1 | import requests |
后记
大三暑假了,在考虑实习,面过开发岗,也面过运维实施岗,然而大公司不要我,小公司我又不想去,某些公司实习生待遇低不说,一天天还各种加班
期间有个上市的医疗信息化公司给我发了运维实施实习生岗的offer,奈何我爸妈觉得这公司压榨员工太严重,扯了一个星期最后决定不去,还是拾起了丢下一个多月的408教材,在B站大学“复学”
本来想着既然不去实习了(面了这么多公司,也不想继续投简历面试了),就在图书馆占个位学校好了,数一英一外加408这么多书,整天从宿舍背到图书馆再背回宿舍对腰椎不好;顺带一提,因为老家没学习的地方,我是“黑”在学校的——我没申请暑假留校;于是在图书馆三层找了个好位置,脚旁就是充电口,方便我给电脑边充电边看网课
这种位置很不好抢,那天上午我把自己所有的资料都放到了那个位置上,厚厚一摞,紧接着当天下午接到通知,为省电,三层不开空调了,我望向一旁图书馆的大落地窗旁苦笑了一下,决定明早把书搬到其他位置
结果第二天上去一看,书都被清走了,一般来说只有上学的时候,为了防止占位,隔一段时间会清书,保证座位的利用率,假期期间是不会清理的;到第一层的服务台找了半天也没找到,还是去回三层接水的时候发现昨天清的书还没来的及送到一层服务台,就这样拿着找来的书去四层找了个头顶滴水的桌子
伞在这期间被偷了两次,现在这把是第三把,虽然是没丢,但伞柄和伞业已“分头行动”,能用是能用,也懒得再买新的了
在四层稳定下来后,我重新审视了自己现在的进度,意识到考408有点悬,就在网上搜自命题学校,发现上海理工大学的自命题只考数据结构和操作系统,难度比408低,数据结构我已经囫囵吞枣地过了一遍,再看看操作系统系统,上海理工好像也不错,我抱着这样的想法开始看操作系统,生活好像也有了希望
翌日连续看了一上午和一中午的操作系统,下午突然想起来上学校官网查一下参考书目,接下来我就看到了上海理工新发的公告,今年所有计算机相关专业改考408
上海理工也成了妄想
继续,继续看老汤头的零基础考研数学,再背点英语单词,专业课?数据结构好了,省内还有三四所双非自命题考的是数据结构
昨天手机显示是晴天,中午图书馆正好停电,前段时间老下雨,床单被罩都没洗。想着趁停电回寝室洗洗,顺便把被子拿出去晒晒。谁知道寝室也停电,等来电了水也没来。只好先把被子拿出去晒
回到图书馆之后越看天越觉得不对劲,心中总有不安,把手机上“晴天”的气象数据发给AI,让它帮我预测下降雨,当看到60%的三十分钟内降雨率时,是的,该下雨了
我连忙跑回寝室收被子,虽然有点湿,好歹还有一面是干的,晚上能睡不是;但我被突然的大雨困在了寝室,伞在图书馆,寝室没有网也没有水,有电,也只有电,打开手机,天气APP里赫然一个太阳:晴,27/36摄氏度
雨下的不小,但短促,雨稍停我就赶回了图书馆,坐在位置上面对电脑里的老汤头,鬼使神差打开了Termius,连上了学校的服务器,一个突如其来的想法闪过,在服务器上部署个ollama,跑几个模型玩玩呗,难点只在于没有ROOT权限
这篇文章的诞生背景就是这样,如果后面还有时间的话,可能会用ollama微调or训练一些模型,到时候也许会再写篇文章记录